A CPU has its instruction set and deals exclusively with machine language instructions, which are nothing more than unique bitpatterns that get routed to the right place for action.
Writing in machine language directly is possible but a very tedious excercise. It is why at some point the assembly language was invented, which abstracts away some repetitive patterns and attempts at making code a bit more human readable. Compared to higher level languages it is still raw and technical, but this does give you the power of controlling exactly how things are done inside the CPU, which is essential for something like a kernel.
In this part, we will do some groundwork with regards to the assembly language that will be useful to more easily understand what’s happening later on. It’s not a full assembly programming guide, but does cover the basics needed for this series.
As mentioned in the previous part about setting up your system, we assume NASM as our assembler and thus everything in these series will be in NASM syntax. For a complete reference of the NASM syntax, the manual is a really good place to start.
Please note that everything written below is how a “normal” program would run in a modern operating system like Linux or Windows. Most of the stuff you read below is not directly applicable to a bootloader or a kernel and we will have to implement most of what you see below yourself. However, it is still good to explore how it is done in existing systems.
Process space
A typical assembly program consists of one or more source files that get compiled and linked into an executable. Within that executable, we can find sections (declared with the SECTION keyword) that serve a specific purpose. The TEXT section contains the executable code your program is made of. The DATA section is used to declare initialized data (in other words with a predefined value) and the BSS section is used to declare uninitialized data (in other words reserved memory without a value).
When your program is executed and loaded into memory by the operating system, a reserved area of virtual memory is assigned to its process called the process space. It has a structure like this:
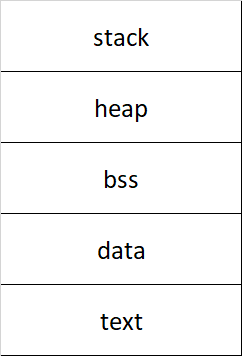
The TEXT, DATA and BSS sections have a size that is known beforehand and they are placed at the lowest memory address in process space. The HEAP and STACK are two dynamically sizing memory areas that traditionally grew towards each other: the HEAP directly adjoins the BSS section and grows upwards (towards higher memory addresses) and the STACK starts at the highest memory address and grows downwards (towards lower memory addresses). While in virtual memory this is no longer necessarily true, it is still almost always the case.
The BSS section is not actually part of your binary (does not take up space) and is initialized to all zeroes in process space as it is reserved memory.
Data sizes
In assembly, declaring static data is about declaring a data location and assigning a label to that location for future reference. When declaring a data location, you need to specify its size. In our 32 bit environment, it can be a BYTE (1 byte), WORD (2 bytes) or DWORD (double word, 4 bytes). A BYTE can contain a value from 0 up to 255 (2^8 possible values), a WORD from 0 up to 65.535 (2^16 possible values) and a DWORD from 0 up to 4.294.967.296 (2^32 possible values).
Some examples:
SECTION .DATA
x db 42 ; Declares a location named "x" of size BYTE with value 42
y dw 1337 ; Declares a location named "y" of size WORD with initial value 1337
z dd 421337 ; Declares a location named "z" of size DWORD with initial value 421337
SECTION .BSS
x resb 42 ; Reserve 42 bytes
y resw 3 ; Reserve 3 words
Operands
Most instructions require at least one operand but many require more than one. When two operands are supplied to an instruction, the first one is typically the destination and the second one the source (note that in AT&T syntax, this is reversed, so be careful when reading other code during your studies).
The operands always represent some type of data as input to the instruction. The data can be constant (e.g. put the number 3 somewhere), reference a register (e.g. take the value from ebx), a location in memory (e.g. 0x40000001), or an expression that calculates an offset (e.g. [esp+4]).
When data is used as an operand to an instruction, it is sometimes necessary to be explicit about the size of this operand and how you want it to be represented. For example, the number 3 can be represented in 8 bits (00000011), in 16 bits (0000000000000011) or in 32 bits (00000000000000000000000000000011). This can be achieved by using a so called size directive, which is specified in the instruction itself:
mov byte eax, 3
mov word eax, 3
mov dword eax, 3
Instructions
We roughly distinguish three categories of instructions: data movement, arithmetic and logic and control flow. There are many instructions available in the X86 instruction set, but we’ll only focus on the most important ones we will encounter on our journey.
For a full set of instructions including all the extensions, you can use this page.
Data movement
To move data between registers and/or memory locations, we have several instructions at our disposal:
; mov
; Copy data from source to destination
; (size is required if ambiguous)
mov (size) destination, source
; push
; Pushes operand to the stack
push operand
; pop
; Pops the stack and puts the result in operand
pop operand
; pushfd
; Pushes the EFLAGS register to the stack
pushfd
; popfd
; Pops the stack and puts the result in
; the EFLAGS register
popfd
; pusha
; Push all 16 bit data registers to the stack in
; the following order: AX, CX, DX, BX, SP, BP, SI, DI
pusha
; popa
; Pops the data registers off the stack in reverse order
; as PUSHA
popa
; pushad / popad
; Identical to pusha/popa but for 32 bit registers
pushad
popad
Arithmetic & logic
Some common ALU operations include:
; add
; Adds source to destination
add destination, source
; sub
; Subtracts source from destination
sub destination, source
; div
; Integer division of the value in AX, DX:AX
; or EAX (depending on size) by divisor
div divisor
; mul
; Multiplies the value in AL, AX or EAX
; (depending on size) by operand
mul operand
; cmp
; Compares the operands and sets the status
; flags in EFLAGS
cmp operand, operand
Flow control
To control the flow during execution of your code, various instructions exist:
; jmp
; Continues execution at address
jmp (segment:)offset
; je/jz
; Jumps to address if the zero flag (ZF) in EFLAGS is 1
je (segment:)offset
jz (segment:)offset
; jne/jnz
; Jumps to address if the zero flag (ZF) in EFLAGS is 0
jne (segment:)offset
jnz (segment:)offset
; jc/jo
; Jumps to address if the carry flag (CF) or overflow flag (OF)
; is 1 respectively
jc (segment:)offset
jo (segment:)offset
; call
; Pushes the return address (next line after the call) to the stack
; and sets EIP to the provided address
call (segment:)offset
; ret
; Pops the stack and sets return address in EIP.
; Depending on calling convention, stacksize to clear may be specified
ret (stacksize)
Assembly formally has no notion of procedure calls. They are basically just jumps back and forth between various locations in executable code using the jmp instruction we described above. However, from a callee (procedure) perspective, you have no idea where to jump once you are done, because you could have been called from anywhere. That’s where call and ret come into play: before call sets EIP (instruction pointer), it pushes the address of the next executable line after the procedure call to the call stack and once the procedure is done, ret pops that return address back off the call stack into EIP so that execution continues where it left off. This makes program flow a lot more natural.
The stack
As you saw earlier, the stack lives in process space. It is a dynamically sized LIFO (last in, first out) data structure that grows and shrinks as items are pushed to it and popped from it (using the push and pop instructions as described earlier).
ESP points to the top of the stack (it always contains the address of the top most item in the stack). Although this is called the top, whenever an item is pushed to the stack, the memory address actually decreases. It thus grows downwards in memory. Whenever an item is popped from the stack, the value in ESP increases.
With every procedure call, as we saw earlier, the return address of the code to execute after the procedure call is pushed to the stack and once the procedure returns, it is popped back off and execution continues. This is not all that the stack is being used for, however. It is also a very easy way to store some data, because you can simply decrease ESP to reserve memory and increase it to discard it again. Besides the return address, it is therefore also used to store more information about the procedure being called, such as its parameters. The block of information about the procedure is called a “stack frame”.
Because ESP changes with every allocation and procedure call, it is an inconvenient way to use as reference when addressing parameters on the stack. Therefore, it is common practice to maintain a second pointer to the start of the stack frame, called the frame pointer (or base pointer); in X86 there is even a reserved register for it: EBP. Addressing parameters from EBP is a lot simpler as within the context of the procedure, the value of EBP never changes.
Modern compilers actually have a setting to base everything on ESP and free up EBP for general purpose use, but keeping EBP for this purpose can be convenient.
Calling conventions
As long as you own all the code, you are free to do whatever you please. You could store parameters in registers, in memory or a combination of both and you can decide who gets to clean up afterwards. However, most of the time you will be sharing code or using shared code. In these cases, it is wise to come to an agreement how parameters are passed, who cleans up and where to find the result of a procedure. These agreements are called “calling conventions”. While there are many of those around, some of them are more common than others. The most commonly used ones are listed below.
Let’s take the following piece of C code to illustrate the conventions used below:
#include <stdio.h>
int add(int x, int y)
{
return x + y;
}
int main()
{
int result = add(10, 20);
printf("Result: %i\n", result);
return 0;
}
cdecl and stdcall
The cdecl calling convention is the default convention used in C and C++. It has the following characteristics:
- Parameters are pushed to the stack from right to left (so, the rightmost parameter is closest to EBP)
- Cleanup is handled by the caller
- Functions are prefixed by an underscore
- The result of the procedure is stored in EAX
This would translate the function call in the sample C code above into the following (simplified) assembly:
; cdecl
_add:
xor eax, eax ; set eax to 0
add eax, [esp+8] ; add x
add eax, [esp+4] ; add y
ret
main:
push dword 20 ; y
push dword 10 ; x
call _add
add esp, 8 ; clear stack frame
; eax now contains the result
Stdcall is identical to cdecl with one small difference: the callee (the procedure itself) is responsible for cleaning up the stack, so in stdcall, the same code would read:
; stdcall
_add:
xor eax, eax ; set eax to 0
add eax, [esp+8] ; add x
add eax, [esp+4] ; add y
ret 8
main:
push dword 20 ; y;
push dword 10 ; x
call _add
; eax now contains the result
fastcall
In the fastcall convention, like in stdcall, the callee is responsible for stack cleanup. Unlike cdecl and stdcall however, the first two parameters are set in registers ECX and EDX instead of the stack (this is faster, hence fastcall):
; fastcall
_add:
xor eax, eax ; set eax to 0
add eax, ecx ; add x
add eax, edx ; add y
ret
main:
mov ecx, 10
mov edx, 20
call _add
; eax now contains the result
Now, with these fundamentals in our pocket, let’s examine the toolkit to compile, link, analyze and debug code in the next chapter!